AWS
[AWS] RDS
gilssang97
2021. 12. 20. 13:02
RDS(Relational DB Service)
관계형 데이터베이스
- 데이터베이스
- 테이블
- 데이터
- 필드
Data Warehousing
- Business Intelligence
- 리포트 작성, 데이터분석시 사용
- 매우 방대한 분량의 데이터 로드시 사용
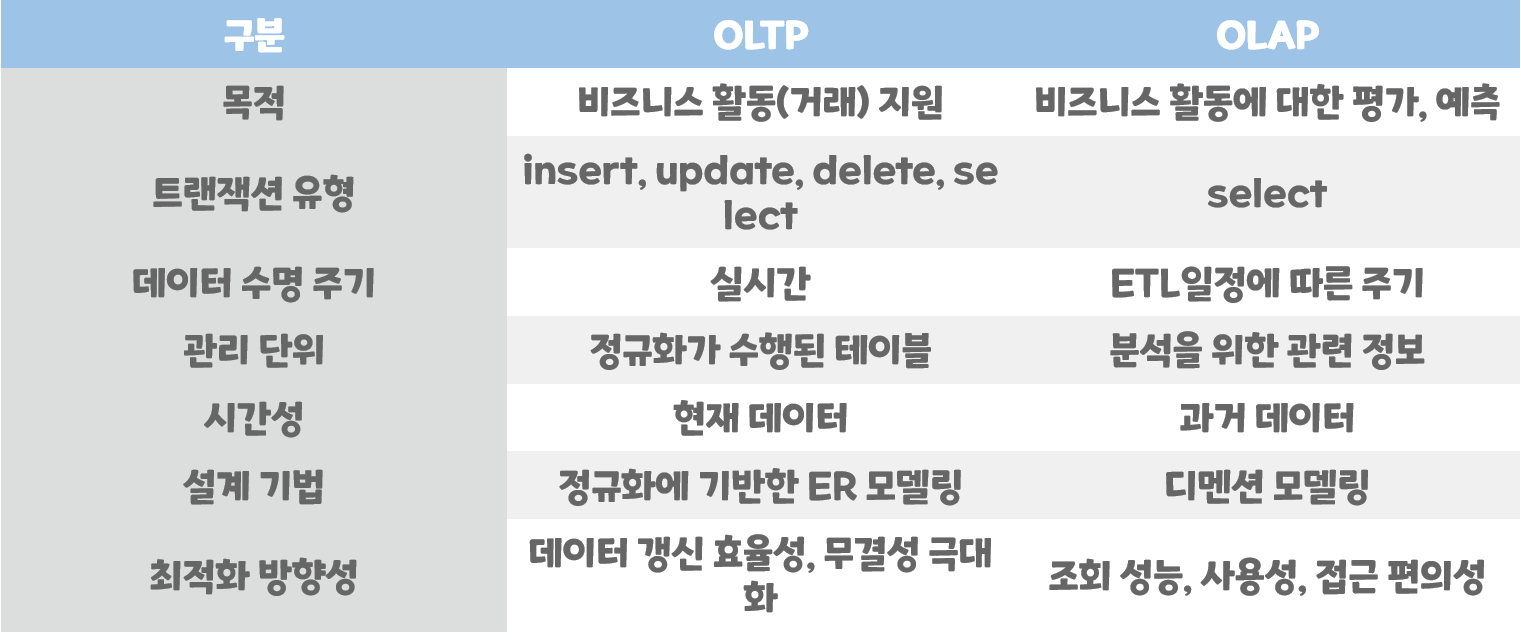
OLTP VS OLAP
- OLTP (Online Transaction Processing)
- INSERT와 같이 종종 사용되어지는, 혹은 규모가 작은 데이터를 불러올때 사용되는 SQL쿼리가 필요할때 사용
- 복수의 사용자 PC에서 발생되는 트랜잭션(Transaction)을 DB서버가 처리하고, 그 결과를 요청한 사용자PC에 결과값을 되돌려주는 과정
- 자주 업데이트되어 데이터 무결성을 중요시여겨야하기에 테이블을 정규화
- Order # 210에만 해당되는 Customer 이름, 주소, 시간 정보 INSERT
- OLAP (Online Analytical Processing)
- 매우 큰 데이터를 불러올때 사용, 주로 덩치가 큰 SELECT 쿼리가 사용됨
- 데이터웨어하우스(DW), 쉽게 말해 DB에 저장되어 있는 데이터를 분석하고, 데이터 분석을 통해 사용자에게 유의미한 정보를 제공해주는 처리방법
- 복잡한 쿼리를 실행하고 트랜잭션이 길기 때문에 많은 시간이 걸리고 빈번히 발생하지 않음
- 특정 회사 부서의 Net Profit, Products
Database Backups
- Automated Backups
- Retention Period(1-35일) 안의 어떤 시간으로 돌아가게 할 수 있음
- AB는 그날 생성된 스냅샷과 Transaction logs(TL)을 참고함
- 디폴트로 AB기능이 설정되어 있으며 백업 정보는 S3에 저장
- AB동안 약간의 I/O suspension이 존재할 수 있음 => Latency
- DB Snapshots
- 주로 사용자에 의해 실행됨
- 원본 RDS Instance를 삭제해도 스냅샷은 존재함 (S3 Bucket 안에)
- AB는 스냅샷이 지워짐
- 백업된 것은 원본과 전혀 다른 객체
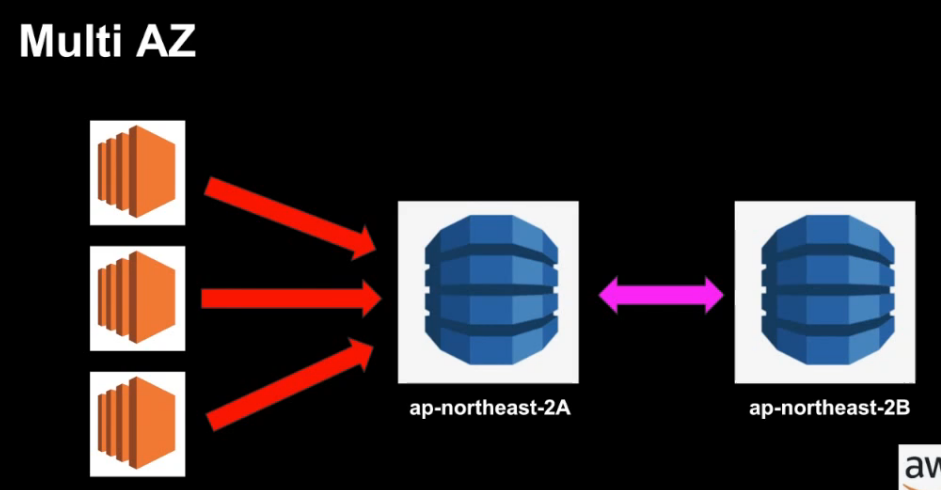
Multi AZ
- 원래 존재하는 RDS DB에 무언가 변화가 생길때 다른 AZ에 똑같은 복제본이 만들어짐 (Synchronize)
- AWS에 의해서 자동으로 관리가 이루어짐
- 원본 RDS DB에 문제가 생길 시 자동으로 다른 AZ의 복제본이 사용됨
- Disaster Recovery Only!
- 성능 개선을 위해서 사용되지는 않음
- 성능 개선을 위해서는 Read Replica를 사용해야함
Read Replica
- Production DB의 읽기 전용 복제본이 생성됨
- 주로 Read-Heavy DB작업시 효율성의 극대화를 위해 사용됨(Scaling)
- Disaster Recovery 용도가 아님!
- 최대 5개 Read Replica DB 허용
- Read Replica의 Read Replica 생성 가능 (단 Latency 발생)
- 각각의 Read Replica는 자기만의 고유 Endpoint 존재

ElasticCache
- 클라우드 내에서 In-Memory 캐시를 만들어줌
- 데이터베이스에서 데이터를 읽어오는 것이 아니라 캐시에서 빠른 속도로 데이터를 읽어옴
- Read-Heavy 어플리케이션에서 상당한 Latency 감소 효과 누림
Memcached
- Object 캐시 시스템
- ElasticCache는 Memcached 프로토콜을 디폴트로 따름
- EC2 Auto Scaling처럼 크기가 커졌다 작아졌다 가능함
- 오픈소스
- 가장 단순한 캐싱 모델이 필요
- Object caching이 주된 목적
- 캐시 크기를 마음대로 Scaling 하기를 원함
Redis
- Key-Value, Set, List와 같은 형태의 데이터를 In-Memory에 저장 가능
- 오픈 소스
- Multi-AZ 지원
- Disaster Recovery 가능
- List, Set과 같은 데이터셋을 사용
- 리더보드처럼 데이터셋의 랭킹을 정렬하는 용도가 필요
- Multi AZ기능을 사용
Memcached vs Redis
공통점
- 1ms 이하의 응답대기시간
- 1ms 이하의 응답시간을 제공합니다. 데이터를 메모리에 저장하기 때문에, 디스크 기반의 데이터베이스보다 빠르게 데이터를 읽을 수 있습니다.
- 개발의 용이성
- 문법적으로 사용하기 쉽고, 개발코드 양 또한 적습니다.
- 데이터 파티셔닝
- 데이터를 여러 노드에 분산하여 저장시킬 수 있습니다. 따라서 수요가 증가할 때 더 많은 데이터를 효과적으로 처리하기 위하여 스케일아웃이 가능합니다.
- 다양한 프로그래밍 언어 지원
- 여러 개발언어를 지원합니다. 자바, 파이썬, C, C++, C#, JavaScript, Node.Js, Ruby, Go 그리고 다른 언어들을 지원합니다.
차이점
Memcached
멀티스레드를 지원하기 때문에,멀티프로세스코어를 사용할 수 있습니다. 따라서, 스케일업을 통하여 더욱 많은 작업처리를 할 수 있습니다.- 1MB까지 저장할 수 있다.
- LRU 삭제 정책만 지원한다.
Redis
- 더욱 다양한 데이터 구조
- 문자열 뿐만 아니라
List,Set,정렬된 Set,Hash,Bit 배열,hyperloglogs(매우 적은 메모리로 집합의 개수를 추정할 수 있는 방법)을 지원합니다. 프로그램에서 위의 다양한 자료구조를 사용할 수 있습니다. 예를 들어,Sorted Set을 활용하여 게임유저의 상위랭크 정보를 쉽게 제공할 수 있습니다.
- 문자열 뿐만 아니라
- Snapshots
- 레디스는 특정시점에 데이터를 디스크에 저장하여 파일 보관이 가능합니다. 또한, 장애상황시 복구에 사용할 수 있습니다.
- 복제
Master — Salves구조로, 여러개의 복제본을 만들 수 있습니다. 따라서 데이터베이스 읽기를 확장할 수 있기 때문에 높은 가용성(오랜 시간동안 고장나지 않음) 클러스터를 제공합니다
- 트랜젝션
- 트렌젝션이란 데이터베이스 상태를 변경시키는 작업 단위를 의미하고, 원자성, 일관성, 독립성, 지속성의 특징을 가지고 있습니다. Redis는 이러한 특징을 지원합니다.
- Pub / Sub messaging
- Publish(발행)과 Sub(구독)방식의 메시지를 패턴 검색이 가능합니다. 따라서 높은 성능을 요구하는 채팅, 실시간 스트리밍, SNS 피드 그리고 서버상호통신에 사용할 수 있습니다.
- 루아 스크립트 지원
- 매우 경량화된 절차스크립트 언어인 루아를 지원합니다. eval 명령어를 사용하여 루아스크립트를 실행시킬 수 있습니다. 따라서, 프로그램을 명료하게하고 성능을 높일 수 있습니다.
- 위치기반 데이터 타입 지원
- Redis는 실시간 위치기반데이터를 지원합니다. 따라서, 두 위치의 거리를 찾거나, 사이에 있는 요소 찾기등의 작업을 수행할 수 있습니다. 이를 활용하여 맛집, 길찾기 그리고 지도기반의 고성능 서비스를 제공할 수 있습니다.
- 512MB까지 저장할 수 있다.