Page, Slice
오늘 다룰 포스트는 Page와 Slice이다.
우리는 흔히 어떤 웹을 돌아다녀도 페이징을 처리한 부분을 자주 찾아볼 수 있다.
우리가 개발을 하면서 구글링을 진행할 때 하단 부분을 바라보면 역시 페이징 처리되어 검색 페이지들이 나열되어 있는 모습을 확인할 수 있다.
이렇게 페이징을 처리하는 이유에 대해서 먼저 알아보자.
우리가 수 많은 데이터가 존재한다고 했을 때, 페이징을 처리하지 않고 모든 데이터들을 한 번에 뿌려준다면 어떻게 될까?
해당 데이터를 DB로부터 가져오는데 엄청난 시간이 소요될 것이다.
그 뿐 아니라, 해당 데이터 자체를 들고 있어야 하기에 엄청난 메모리의 소비가 존재할 것이다.
또한, 사용자들이 해당 게시물들을 모두 보게 하게끔 만들기에 용이하지 못하다.
그래서 우리는 모든 데이터들에 대해 개수에 대한 기준을 만들어 해당 개수만큼 가져오면서 다음 데이터에 대해서는 페이지 형태로 나타낼 수 있게 한다.
하지만 위에서는 Page와 Slice 두 가지를 언급했다.
이에 대해 알아보자.
Page는 다음 사진과 같이 단순 우리가 생각하는 페이지이다.

이처럼 정해진 데이터의 개수를 기준으로 페이지를 계산하여 페이지를 통해 다음 데이터를 받아볼 수 있다.
Slice의 경우에도 비슷하다.
Slice의 경우에는 요즘 우리가 사용하는 인스타그램에서 찾아볼 수 있다.
인스타그램에서 다음 포스트를 확인해보려고 할 때, 단순 스크롤을 내려가며 계속적으로 확인할 수 있다.
이러한 부분을 흔히 무한 스크롤이라고 한다.
이러한 부분에서는 Page와 달리 페이지 계산이 불필요하다.
보통 페이지를 계산하기 위해서는 전체 데이터의 개수 / 데이터를 로드할 기준 개수를 통해 구하기에 Slice는 Page에 비해 전체 데이터의 개수를 알기 위해 Count Query를 사용할 필요가 없으며 단순 다음 데이터가 존재하는지에 대한 여부를 파악하면 될 것이다.
이러한 부분들에 있어 우리는 코드로 직접 구현해보려고 한다.
시작하기에 앞서, 요구사항을 미리 살펴보자.
- 스터디 내부에 존재하는 게시판의 게시글들에 대해서는 페이징 처리를 진행
- 게시글은 10개씩 로드
- 스터디에 대해서는 슬라이싱 처리를 진행
- 스터디는 6개씩 로드
우리는 위에서 살펴볼 두 가지에 대해 모두 구현처리해보려고한다.
먼저, 페이징 처리부터 구현해보자.
우리가 게시글을 10개씩 끊어서 불러와야하기에 SQL에서의 offset과 limit을 적극활용해야한다.
이를 위한 처리로 가독성 높은 쿼리 처리를 위해 QueryDSL을 활용해보았다.
보통 QueryDSL은 동적 쿼리를 처리하는데 용이하고 쿼리를 직접 타이핑하는 것과 달리 컴파일 시점에 오류를 잡아줘 상당히 용이하다.
이러한 부분에 있어 사용해보기로 하였다.
먼저, Page의 구현체인 PageImpl 클래스에 대해 알아보자.
PageImpl에 대해 알아보기 위해 생성자를 살펴보면 다음과 같다.
// PageImpl
public PageImpl(List<T> content, Pageable pageable, long total) {
super(content, pageable);
this.total = pageable.toOptional().filter(it -> !content.isEmpty())//
.filter(it -> it.getOffset() + it.getPageSize() > total)//
.map(it -> it.getOffset() + content.size())//
.orElse(total);
}
// Pageable
static Pageable ofSize(int pageSize) {
return PageRequest.of(0, pageSize);
}
// PageRequest
public static PageRequest of(int page, int size) {
return of(page, size, Sort.unsorted());
}총 세 가지의 인자를 입력받는다.
담길 정보인 Content, Page의 정보를 담고 있는 Pageable, 총 개수를 담고 있는 total로 이루어져있다.
Pageable은 Pageable 자체나 Pageable을 구현한 구현체인 PageRequest를 받을 수 있다.
Pageable의 경우 요청 페이지를 0으로 하는 반면 PageRequest는 페이지를 지정할 수 있다.
그래서 우리는 페이징을 진행하는데 있어서는 PageRequest 구현체를 사용할 것이다.
이제, 실제 DB에서 요청하는 쿼리에 대해 살펴보자.
@Override
public Page<StudyArticle> findAllOrderByStudyArticleIdDesc(Long boardId, Pageable pageable) {
// Load Data
List<StudyArticle> studyArticles = jpaQueryFactory
.selectFrom(studyArticle)
.innerJoin(studyArticle.member, member).fetchJoin()
.where(studyArticle.studyBoard.id.eq(boardId))
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
// Count Data
JPAQuery<StudyArticle> countQuery = jpaQueryFactory
.selectFrom(studyArticle)
.where(studyArticle.studyBoard.id.eq(boardId));
return PageableExecutionUtils.getPage(studyArticles, pageable, countQuery::fetchCount);
}우리는 Page에 담기 위한 Content를 받아와야하기 때문에 Load Data와 같은 쿼리를 전송했다.
여기서 pageable에 담은 페이지 정보를 통해 페이징 처리를 진행했다. (offset, limit)
하지만 쿼리를 작성할 때 주의해야할 점은 페이징 처리를 할 때 N:1 관계의 경우에는 패치 조인하여 페이징 처리가 가능하지만 1:N의 경우에 패치조인하게되면 카르테시안 곱에 의한 데이터 뻥튀기 문제로 페이징 처리가 되지 않는다.
그러기에 이 부분을 신경써야한다.
QueryDSL에서 fetch()를 통해 데이터를 가져오긴 하지만 fetchResult()를 통해 카운트 정보까지 가져와 페이징 처리로 한번에 사용할 수 있지만 이 부분은 효율적이지 못하다.
단순 Count를 하는 쿼리임에도 조인 등 다양한 불필요한 처리를 하기에 더욱 시간이 오래 걸리는 비효율적인 Count 쿼리가 되버린다.
그렇기 때문에 Count 쿼리를 따로 작성해 처리했다.
마지막에 단순 PageImpl 생성자로 처리하지 않고 PageableExcutionUtils를 통해 getPage 처리한 부분에는 이유가 있다.
페이지가 한 페이지 밖에 없거나 마지막 페이지인 경우 굳이 Count 쿼리를 날리지 않아도 되는데 전자의 경우(생성자 처리)는 쿼리를 날리기에 비효율적이다.
이를 방지하기 위해 PageableExcutionUtils.getPage를 통해 처리했다.
다음과 같이 작성된 페이징 쿼리에 대해 테스트를 진행해보자.
테스트를 위해 초기화된 데이터는 다음과 같이 한 게시판에 13개의 글이 작성되게 하였다.
@BeforeEach
void beforeEach() {
...
StudyArticle studyArticle1 = new StudyArticle("공지사항 테스트 글", "공지사항 테스트 글입니다.", 0L, memberA, studyBoard1);
StudyArticle studyArticle2 = new StudyArticle("자유게시판 테스트 글", "자유게시판 테스트 글입니다.", 0L, memberA, studyBoard1);
StudyArticle studyArticle3 = new StudyArticle("알고리즘 테스트 글", "알고리즘 테스트 글입니다.", 0L, memberA, studyBoard1);
studyArticleRepository.save(studyArticle1);
studyArticleRepository.save(studyArticle2);
studyArticleRepository.save(studyArticle3);
for (int i = 0; i < 10; i++) {
StudyArticle studyArticleTest = new StudyArticle("알고리즘 테스트 글", "알고리즘 테스트 글입니다.", 0L, memberA, studyBoard1);
studyArticleRepository.save(studyArticleTest);
}
}이제 본격적인 테스트를 진행해보자.
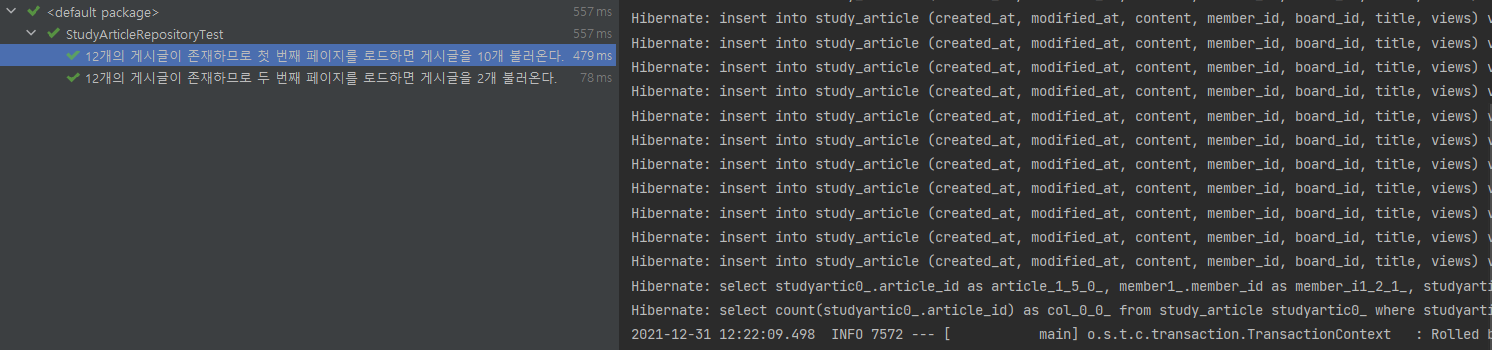
우리가 10개씩 페이징한다고 했을 때 어떻게 처리되는지 확인하기 위해 두 가지의 케이스를 작성했다.
첫 번째 페이지를 로드한다.
- 13개의 게시글이 존재하므로 첫 번째 페이지를 로드하면 게시글을 10개 불러온다. (다음 페이지가 존재한다.)
두 번째 페이지를 로드한다.
- 13개의 게시글이 존재하므로 두 번째 페이지를 로드하면 게시글을 3개 불러온다. (다음 페이지가 존재하지 않는다.)
@Test
@DisplayName("13개의 게시글이 존재하므로 첫 번째 페이지를 로드하면 게시글을 10개 불러온다.")
public void findAllOrderByStudyArticleIdDesc() throws Exception {
//given
//when
Page<StudyArticle> studyArticles = studyArticleRepository.findAllOrderByStudyArticleIdDesc(studyBoard1.getId(), PageRequest.of(0, 10));
//then
Assertions.assertEquals(2, studyArticles.getTotalPages());
Assertions.assertEquals(10, studyArticles.getNumberOfElements());
Assertions.assertEquals(true,studyArticles.hasNext());
}
@Test
@DisplayName("13개의 게시글이 존재하므로 두 번째 페이지를 로드하면 게시글을 2개 불러온다.")
public void findAllOrderByStudyArticleIdDesc2() throws Exception {
//given
//when
Page<StudyArticle> studyArticles = studyArticleRepository.findAllOrderByStudyArticleIdDesc(studyBoard1.getId(), PageRequest.of(1, 10));
//then
Assertions.assertEquals(2, studyArticles.getTotalPages());
Assertions.assertEquals(3, studyArticles.getNumberOfElements());
Assertions.assertEquals(false, studyArticles.hasNext());
}다음과 같은 두 개의 테스트를 진행했을 때 결과는 다음과 같이 잘 통과하는 모습을 보여준다.
그러면 이제 서비스 레이어에 비지니스 로직을 작성해보자.
우리는 얻어진 Page 결과를 통해 Dto로 변환하여 이를 반환해야한다.
이를 위해 PageResponse를 위한 Dto를 생성하였다.
생성하기 위해서는 정적 팩토리 메서드를 구성하여 진행했다.
코드 자체는 단순 페이지로 불러온 데이터를 Dto가 변환하여 리턴한다.
@Override
public PageResponseDto findAllArticles(Long boardId, Integer page, Integer size) {
Page<StudyArticle> studyArticle = studyArticleRepository.findAllOrderByStudyArticleIdDesc(boardId, PageRequest.of(page, size));
return PageResponseDto.create(studyArticle, StudyArticleFindResponseDto::create);
}그러면, Dto 생성 처리에 대해 살펴보자.
우리가 페이징 처리를 StudyArticle에 대해서가 아닌 다른 엔티티에 대해서도 적용할 수 있기에 제네릭을 이용해 구성하였다.
@Data
@NoArgsConstructor
@AllArgsConstructor
public class PageResponseDto <D> {
private int numberOfElements;
private int totalPages;
private boolean hasNext;
private List<D> data;
public static <E, D> PageResponseDto create(Page<E> entity, Function<E, D> makeDto) {
List<D> dto = convertToDto(entity, makeDto);
return new PageResponseDto(entity.getNumberOfElements(), entity.getTotalPages(), entity.hasNext(), dto);
}
private static <E, D> List<D> convertToDto(Page<E> entity, Function<E, D> makeDto) {
return entity.getContent().stream()
.map(e -> makeDto.apply(e))
.collect(Collectors.toList());
}
}PageResponseDto는 Page에 대한 정보를 담는 큰 틀이고, 그 안에 각 엔티티를 Dto로 변환한 객체를 담고 있다고 생각하면 된다.
이러한 부분에 대해서 엔티티를 Dto로 변환하는 메소드가 필요해 이를 함수형 인터페이스인 Function을 통해 받아와 이를 처리해주었다.
그리고 실제 필요한 정보인 개수, 페이지 개수, 다음 정보가 있는지에 대한 정보, 데이터(Dto)를 담아 변환하였다.
그렇다면 컨트롤러를 보자.
우리는 사용자로부터 페이지 정보와 크기를 입력받아와야 이를 처리할 수 있기에 이에 대한 정보를 받아와야한다.
@ApiOperation(value = "스터디 게시글 모두 찾기", notes = "스터디에 포함된 게시글을 모두 찾는다.")
@GetMapping
public SingleResult<PageResponseDto> findStudyArticles(@PathVariable Long studyId, @PathVariable Long boardId,
@RequestParam Integer page, @RequestParam Integer size) {
return responseService.getSingleResult(studyArticleService.findAllArticles(boardId, page, size));
}그렇기에 파라미터로 입력받은 해당 정보를 @RequestParam을 통해 받아와 이를 반환하도록 하였다.
페이징을 처리하는 장정이 끝났다.
하지만 아직 Slice에 대한 부분은 끝나지 않았다.
이제 Slice를 어떻게 처리하는지에 대해 알아보자.
Slice는 Page와 비슷하다.
오히려 간편하다고 할 수 있다.
Page에서는 전체 페이지 수를 카운트해야하지만 Slice에서는 그럴 필요가 없다 Slice에서는 다음 페이지가 있는지만 있는지 확인하면 된다.
하지만 Slice에서는 고려해야할 부분이 한 가지 존재한다.
다음과 같은 예시를 살펴보자.
기존에 6개의 스터디가 존재하고 페이지당 3개씩 뿌린다고 가정했을 때 다음과 같이 페이지 구성이 될 것이다.
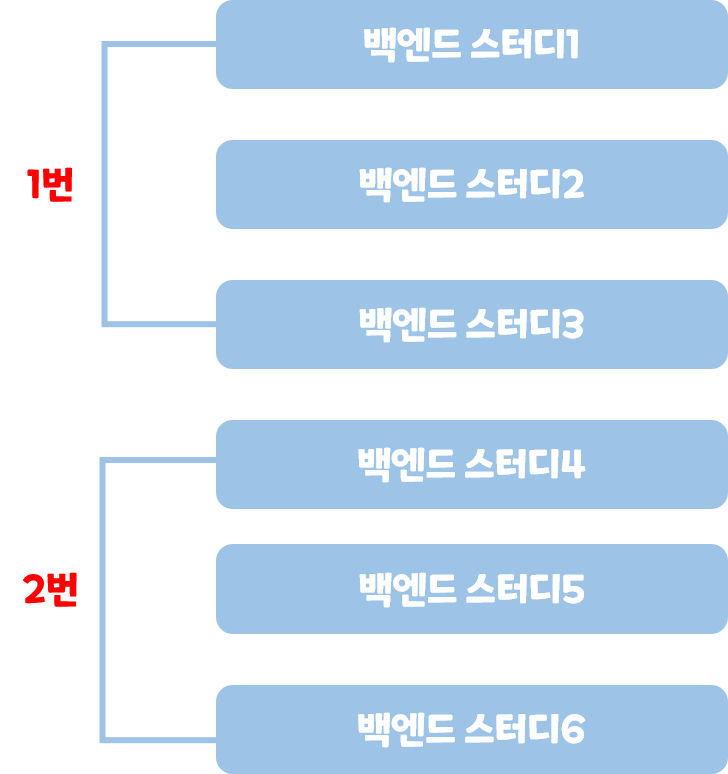
그런데 그 뒤에 새로운 스터디가 추가적으로 2개가 생성된다면 다음과 같이 페이지 구성이 변할 것이다.

기존 1번페이지를 보고 있던 사용자는 2번 페이지를 보려고 할 때 기존 2번에서 봤던 내용을 겹쳐서 보게될 것이다.

이러한 부분을 해결하기 위해 다음과 같은 방법을 고려해보았다.
기존 페이지를 통해 요청하는 것이 아니라 지금 보고 있는 데이터 중 마지막 데이터의 ID(PK)값을 받아와 해당 ID를 기준으로 데이터를 받아오면 되는 것이다.
이 부분에 대해서는 Data JPA를 활용하여 진행해보자.
@Query("select s from Study s " +
"left join fetch s.member " +
"where s.department = :department and s.id < :studyId " +
"order by s.id desc")
Slice<Study> findAllOrderByStudyIdDesc(@Param("studyId") Long lastStudyId,
@Param("department") String department, Pageable pageable);studyId 이전에 있는 데이터들을 무시하고 해당 페이지 만큼의 데이터를 가져온다. (department는 과 별로 데이터를 가져오는 필터링 역할을 하는데 이곳에서는 별로 중요하지 않다.)
그리고 최근에 만들어진 순으로 데이터를 가져오기 위해 정렬을 진행했다.
이 부분을 실제로 테스트해보자.
데이터는 다음과 같이 구성했다.
스터디를 총 10개를 만들었고 이를 6개씩 찢어 받아오려고 한다.
@BeforeEach
void beforeEach() {
...
for (int i = 0; i < 10; i++) {
Study study = new Study("백엔드 모집"+i, List.of("백엔드", "스프링", "JPA"), "백엔드 모집합니다.", "C:\\Users\\Family\\Pictures\\Screenshots\\2.png", "컴퓨터공학과",
StudyState.STUDYING, RecruitState.PROCEED, StudyMethod.FACE, 2L, "2021-12-25", memberA, new ArrayList<>(), new ArrayList<>());
studyRepository.save(study);
}
}처음에는 마지막 데이터가 없기에 해당 데이터보다 ID가 작은 것을 받아오기 위해 INFINITY로 설정했고, 두 번째의 경우에는 6번째에 있는(마지막에 위치한) 데이터의 ID(PK)를 찾아 이를 통해 찾았다.
@Test
@DisplayName("컴퓨터공학과 스터디를 6개씩 Slice로 조회하기에 뒤에 4개가 남아있다.")
public void findAllStudyBySlice() throws Exception {
//given
Long lastStudyId = Long.MAX_VALUE;
Pageable pageable = Pageable.ofSize(6);
//when
Slice<Study> studies = studyRepository.findAllOrderByStudyIdDesc(lastStudyId,"컴퓨터공학과", pageable);
//then
Assertions.assertEquals(6, studies.getNumberOfElements());
Assertions.assertEquals(true, studies.hasNext());
}
@Test
@DisplayName("컴퓨터공학과 스터디를 6개씩 Slice로 조회하지만 4개만 남아있기에 4개가 조회되고 뒤에 남아있지 않다.")
public void findAllStudyBySlice2() throws Exception {
//given
Long lastStudyId = studyRepository.findStudyByTitle("백엔드 모집4").get(0).getId();
Pageable pageable = Pageable.ofSize(6);
//when
Slice<Study> studies = studyRepository.findAllOrderByStudyIdDesc(lastStudyId,"컴퓨터공학과", pageable);
//then
Assertions.assertEquals(4, studies.getNumberOfElements());
Assertions.assertEquals(false, studies.hasNext());
}다음과 같이 테스트의 결과가 잘 나온 모습을 확인할 수 있다.
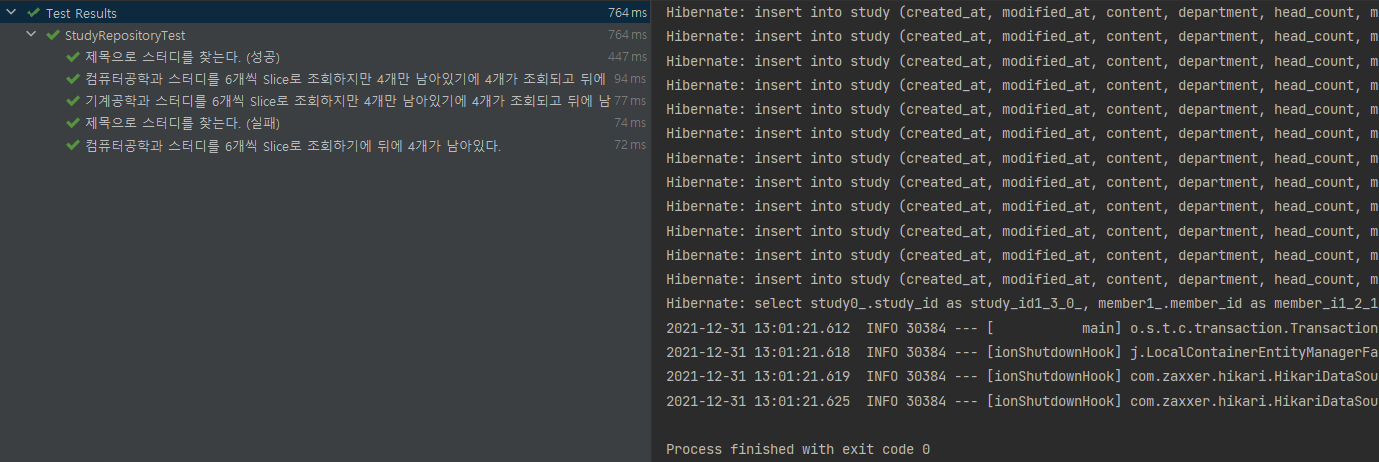
위의 사진에서와 같이 Count 쿼리를 안날리고 진행하는 모습을 확인할 수 있다.
이를 서비스 레이어에서 로직을 구현해보자.
@Override
public SliceResponseDto findAllStudiesByDepartment(Long lastStudyId, String department, Integer size) {
Slice<Study> study = studyRepository.findAllOrderByStudyIdDesc(lastStudyId, department, Pageable.ofSize(size));
return SliceResponseDto.create(study, StudyFindResponseDto::create);
}페이징과 마찬가지로 찾아와 SliceResponseDto로 바꿔주었는데 SliceResponseDto도 PageResponseDto와 마찬가지이지만 단순 페이지의 개수가 존재하지 않는다.
@Data
@NoArgsConstructor
@AllArgsConstructor
public class SliceResponseDto <D> {
private int numberOfElements;
private boolean hasNext;
private List<D> data;
public static <E, D> SliceResponseDto create(Slice<E> entity, Function<E, D> makeDto) {
List<D> dto = convertToDto(entity, makeDto);
return new SliceResponseDto(entity.getNumberOfElements(), entity.hasNext(), dto);
}
private static <E, D> List<D> convertToDto(Slice<E> entity, Function<E, D> makeDto) {
return entity.getContent().stream()
.map(e -> makeDto.apply(e))
.collect(Collectors.toList());
}
}그리고 실제 Controller를 보자.
여기도 마찬가지로 page를 파라미터로 받아오는 것이 아니라, 마지막 ID를 받아온다.
@ApiOperation(value = "스터디 정보 로드", notes = "모든 스터디 정보를 얻어온다.")
@GetMapping
public SingleResult<SliceResponseDto> findAllStudies(@RequestParam Long studyId, @RequestParam String department,
@RequestParam Integer size) {
return responseService.getSingleResult(studyService.findAllStudiesByDepartment(studyId, department, size));
}
다음과 같이 Page와 Slice에 대한 부분을 살펴보고 실제 구성해보았다.
이번 부분을 통해 Page와 Slice에 대한 차이와 이를 어떻게 이용하고 왜 이용하는지에 대해 더 자세히 알게되었다.
페이징과 슬라이싱은 상당히 많이 사용되는 부분 중 하나이기에 잘 알아두어야 한다.
'개발일지' 카테고리의 다른 글
| @ElementCollections 사용기 (0) | 2022.01.01 |
|---|---|
| @Embeddable 활용기 (0) | 2021.12.31 |
| Cascade vs @Delete (1) | 2021.12.28 |
| Cascade의 오해 (0) | 2021.12.26 |
| 알림 기능을 구현해보자 - SSE(Server-Sent-Events)! (8) | 2021.12.24 |