다들 Spring과 JPA 조합으로 구현을 할 때, N+1문제를 한번씩 들어봤을 것이다.
이번 포스트는 JPA에서의 단골손님인 N+1문제에 대해 알아보려고 한다.
N+1이란

우리는 조회, 수정 등의 이유로 다양한 엔티티들을 조회하곤 한다.
각각의 엔티티들은 연관관계를 가질 수도, 가지지 않을 수도 있다.
N+1문제는 연관관계를 가지는 엔티티들 중에서 연관 관계에서 발생하는 이슈이다.
A라는 엔티티(N)가 B라는 엔티티(1)와 연관관계를 가지고 있다고 하자.
우리가 A라는 엔티티를 조회할 때, B라는 엔티티에 대한 데이터를 조회하기 위해 B라는 데이터의 개수(N)만큼 조회 쿼리가 추가로 발생하는 것을 의미한다.
이 부분이 실제로 발생하는 부분에 대해서 실제 예제를 통해 살펴보자.
엔티티
우리는 게시판을 구현하기 위한 학생(Student) 엔티티, 게시물(Board) 엔티티, 댓글(Comment) 엔티티가 존재한다.
이 셋의 관계는 다음과 같다.

- 학생은 게시물과 연관 관계를 맺고있다.
- 게시물은 학생, 댓글과 연관 관계를 맺고있다.
- 댓글은 게시물, 댓글(Self)과 연관 관계를 맺고있다.
조회 테스트
우리는 엔티티들로 간단한 조회 테스트를 진행해보자.
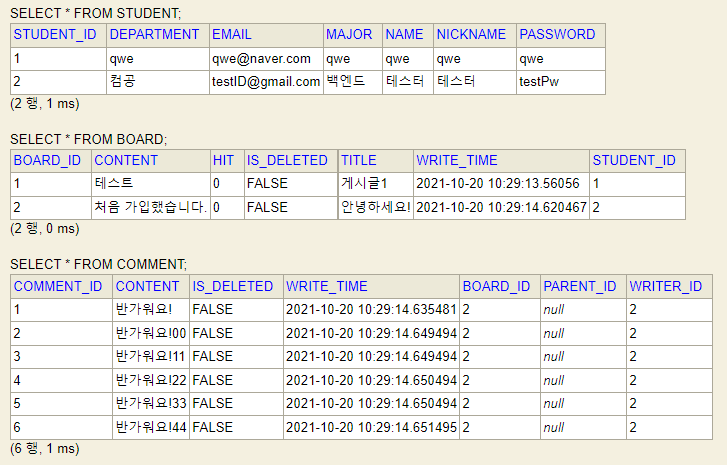
어떤 한 학생이 1개의 게시물을 작성하였다.
해당 게시물에는 1개의 댓글이 있고 해당 댓글에는 5개의 답글이 존재한다고 하자.
// 학생 가입
Student student = new Student("testID@gmail.com", "testPw", "테스터", "테스터", "컴공", "백엔드");
Student joinStudent = studentService.join(student);
// 게시물 작성
Board board = new Board("안녕하세요!", joinStudent, "처음 가입했습니다.", LocalDateTime.now(), false, 0);
Board post = boardService.post(board);
// 댓글 작성
CommentAddForm parentCommentAddForm = new CommentAddForm(post.getId(), joinStudent.getId(), null, "반가워요!");
Comment parentComment = commentService.addComment(parentCommentAddForm);
// 답글 작성
for (int i = 0; i < 5; i++) {
commentService.addComment(new CommentAddForm(post.getId(), joinStudent.getId(), parentComment.getId(), "반가워요!"+i+i));
}
작성자가 자신이 작성한 게시물에 대한 모든 댓글 정보를 알고싶다.
그래서 우리는 해당 부분을 수행하기 위한 쿼리를 작성하고 실행하였다.
em.flush();
em.clear();
List<Comment> findComments = commentService.findComments(board.getId());
System.out.println("findComments = " + findComments);- 영속성 컨텍스트를 비우기 위해 flush(), clear()를 진행하고 수행하였다.
- 해당 학생이 작성한 게시글에 작성된 댓글들에 대해 조회해보았다. (1개 작성)
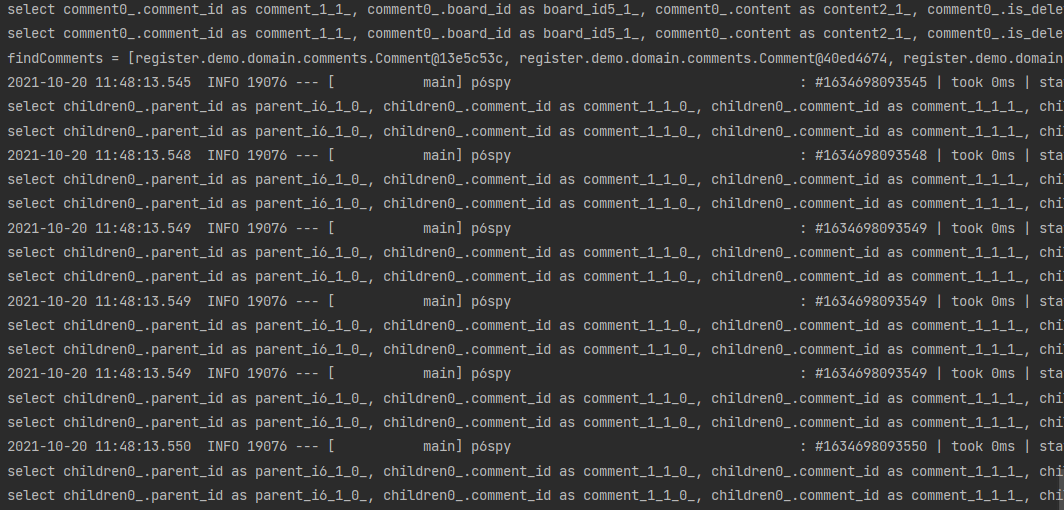
분명, 쿼리가 1개가 나가야 정상인 것 같은데 쿼리가 6개가 나가고있다.
자세히 쿼리를 보면, 댓글들을 탐색하는 쿼리 1개, 해당 댓글에 대한 답글을 조회하는 쿼리 6개가 나가고 있다.
우리는 단지 댓글만 조회하려고 했으나 답글까지 다 끌어오는 모습을 볼 수 있다.
이 부분에 대해서는 댓글(Comment) 엔티티를 확인해보면 알 수 있다.
public class Comment {
...
@OneToMany(mappedBy = "parent", cascade = CascadeType.ALL, fetch = FetchType.EAGER)
private List<Comment> children = new ArrayList<>();
...
}- 해당 연관관계에 대해서 FetchType을 EAGER로 설정해두었다.
- xToMany의 경우 기본 패치 전략이 LAZY이지만 예시로 사용하기 위해 임의로 EAGER로 변경해두었다.
그렇다. 우리가 쿼리를 6번 더 호출한 이유는 comment가 들고있는children을 조회하기 위한 것이였다.
이 비밀은 패치 전략 속에 있다. 이 부분에 대해서 알아보자.
FetchType이란
위에서 언급한 것처럼 엔티티들간에 연관관계가 존재할 수 있다.
이에 따라, FetchType을 통해서 연관 관계가 있는 엔티티까지 끌어올지에 대한 여부를 결정할 수 있다.
그에 따라, FetchType은 EAGER과 LAZY를 제공해주는데 두 가지에 대해 각각 알아보자.
FetchType.EAGER
이 부분은 위에서 살펴봤다싶이, 우리가 children을 사용하지 않아도 일단 무조건 끌어오는 것이다.
List<Comment> findComments = commentService.findComments(board.getId());
System.out.println("findComments = " + findComments);그래서 우리는 위의 코드처럼 단순 comment만 사용하고 children은 전혀 사용하지 않는데도 일단 하나씩 조회해서 다 끌어오는 것이다.
현재 댓글이 총 6개가 있다.(댓글 1개, 답글 5개)
댓글 6개 모두 BoardId는 동일하게 가지고 있으므로 1개의 쿼리로 6개 모두 조회할 수 있다.
하지만, 각각의 댓글에 존재하는 children을 찾기 위해 6개의 쿼리가 더 나간다
이에 따라, 우리가 실무에서 EAGER을 사용하여 처리하는 것은 N+1문제를 초래하므로 무조건 지양해야할 부분 중 하나이다.
그렇다면 우리가 LAZY를 통해서 이를 해결할 수 있을까? 이에 대해 살펴보자.
FetchType.LAZY
이 부분은 살펴보지 않았지만 간단한 예제를 통해서 살펴보자.
public class Comment {
...
@OneToMany(mappedBy = "parent", cascade = CascadeType.ALL)
private List<Comment> children = new ArrayList<>();
...
}위에서 언급한 것처럼 xToMany의 경우에는 패치 전략은 기본적으로 LAZY이므로 이를 생략하므로써 간단히 LAZY로 설정할 수 있다.
이 상태에서 아까와 같은 쿼리를 실행하면 어떤 결과를 출력할까?

쿼리를 더이상 N만큼 더 출력하지 않는다.
그 비밀은 바로 여기에 있다.
LAZY의 경우 children을 실제 엔티티에서 끌어오지 않고 프록시를 받아온다.
프록시를 받아오기 때문에 실제 호출때는 단순 프록시를 넣어놓고 실제 children에 있는 객체를 끌어올 필요가 없다.
우리가 다음 코드에서 볼 수 있듯이 children에 대해서는 전혀 건드리지 않고 있기 때문에 children을 끌어올 필요가 없어 조회하지 않는다.
List<Comment> findComments = commentService.findComments(board.getId());
System.out.println("findComments = " + findComments);그런데, 우리가 실제로 해당 객체를 불러오고 싶을 때는 다음과 같이 실제로 호출을 하게되면 프록시에서 해당 객체에서 조회해 꺼내온다.
List<Comment> children = findComments.get(0).getChildren();
Comment childComment = children.get(0);그렇다면 해당 객체를 사용할 때만 쿼리를 불러 조회하게 된다.
그래서 우리는 실무에서 EAGER의 사용을 최대한 지양하고 LAZY의 사용을 최대한 지향해야한다.
하지만, 이 부분에 대해서 우리가 N+1의 문제를 근본적으로 해결한다고 볼 수 있을까?
정답은 아니요이다.
다음 예제를 살펴보자.
for (Comment findComment : findComments) {
for (Comment child : findComment.getChildren()) {
child.getContent();
}
}
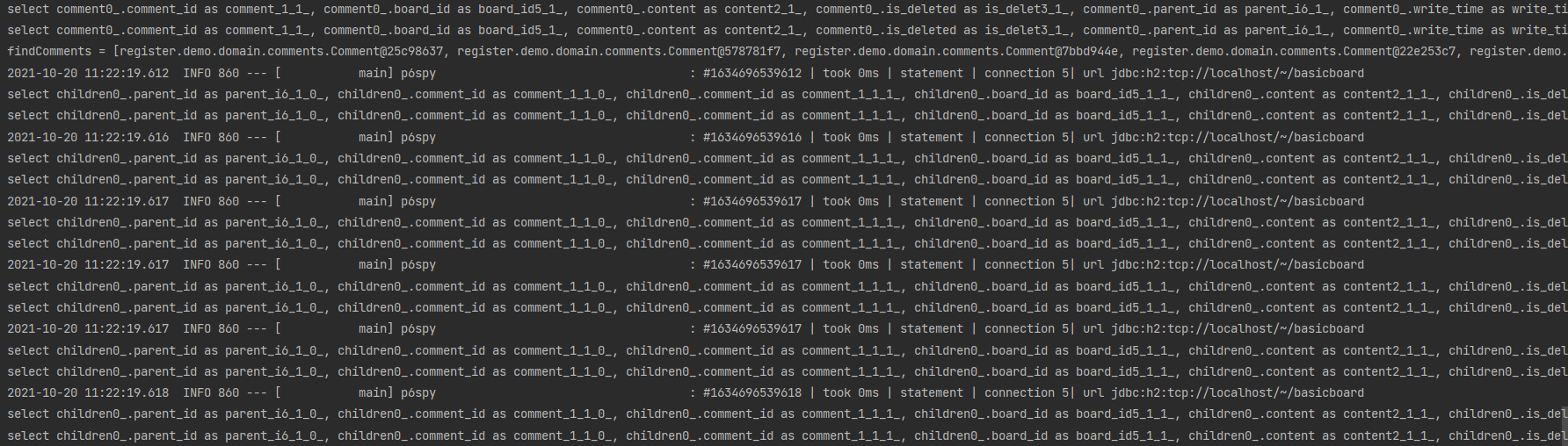
아까는 1개의 답글에 대해서만 처리했기때문에 1개의 쿼리가 나갔다.
하지만, 전체적인 답글에 대해 처리하기를 원한다면? 바로 전체를 조회하는 문제점은 똑같다.
LAZY방식이 좋긴하지만 이러한 경우에 우리는 해결할 방법을 찾아야 할 것이다.
해결방안
Fetch Join
우리는 해당 엔티티를 끌어올 때, 연관 관계를 가진 객체를 한 번에 끌어올 수 있는 기능을 사용할 수 있다.
바로 fetch join이다.
이를 사용하는 방법은 다음과 같다.
@Query("select c from Comment c left join fetch c.board join fetch c.writer join fetch c.children ch where c.board.id = :boardId")
List<Comment> findAllComments(@Param("boardId") Long boardId);한 번에 끌어오고 싶은 객체들을 fetch join대상으로 잡으면 된다.
그러면 다음과 같이 깔끔하게 쿼리 1번에 처리할 수 있게 된다.

fetch join의 경우 별칭을 사용하면 하위의 하위 타입까지 끌어올 수 있다. (단, 불필요한 쿼리문이 추가될 수 있다.)
또한, Collection을 한 번에 두 개 이상 fetch join하는 것을 허용하지 않는다.
@EntityGraph
fetch join말고 연관 관계를 가진 객체를 한 번에 끌어올 수 있는 기능을 제공하는 @EntityGraph를 사용할 수 있다.
이는 attributePaths에 쿼리 수행시 바로 끌어올 필드명을 지정하면 바로 가져온다. (원본의 쿼리를 깔끔하게 그대로 유지한다.)
@EntityGraph(attributePaths = {"board", "writer", "children"})
@Query("select c from Comment c where c.board.id = :boardId")
List<Comment> findAllComments(@Param("boardId") Long boardId);

다음과 같이 쿼리 1번에 잘 끌어오는 모습을 확인할 수 있다.
Fetch Join과 @EntityGraph
특징
- fetch join의 경우 Inner Join을 시행한다.
- @EntityGraph의 경우 Outer Join을 시행한다.
문제점과 해결방법
카르테시안 곱이 발생하여 조인의 결과가 원래 데이터에 비해 증가할 수 있다.
- 일대다 필드의 타입을 Set으로 선언하는 것이다.
- distinct를 사용하여 중복을 제거한다.
BatchSize
또 다른 방법으로는 하이버네이트가 제공하는 org.hibernate.annotations.BatchSize 어노테이션을 활용하면 설정한 size만큼의 데이터를 IN절을 통해서 미리 꺼내와 이 문제를 해결할 수 있다.
public class Comment {
...
@BatchSize(size=100)
@OneToMany(mappedBy = "parent", cascade = CascadeType.ALL, fetch = FetchType.EAGER)
private List<Comment> children = new ArrayList<>();
...
}

우리가 지연 로딩을 사용하고 있다면 엔티티를 사용하는 최초 시점에 100개를 미리 로딩해두고, 101개부터 사용 시점에 다음 SQL을 추가로 호출함으로써 다음 100개를 추가적으로 로딩한다.
이 방법은 위에서 말한 OneToMany 등에서 발생하는 객체와 DB와의 패러다임 상충문제, Collection 두 개 이상의 문제일 때 유용하게 사용될 수 있다.
마무리
JPA를 사용하면서 N+1은 상당히 자주 부딪히는 문제 중 하나이기에 fetch join이나 EntityGraph의 경우를 통해 XToOne의 경우에서 유용하게 활용하여 이를 방지하자.
하지만, 이러한 부분이 아닌 경우 BatchSize를 통해서 접근하여 해결해보도록 노력해보자.
이 부분에 대해서는 아직 부족한 부분이 많지만 계속 더 채워나갈 생각이다.
'스프링' 카테고리의 다른 글
| [Querydsl] Querydsl 기본적인 사용 및 게시물 동적 검색 구현 (5) | 2021.10.21 |
|---|---|
| [Spring] 파일 및 이미지 업로드 (4) | 2021.10.20 |
| [Spring] API Exception (With Validation) (0) | 2021.09.27 |
| [Spring] 오류 페이지 (0) | 2021.09.27 |
| [Spring] 필터, 인터셉터 (0) | 2021.09.26 |